Previous page : The hyperbolic functions
Next page : Differential Equations
Integrals
- Integrals – a definition
- The fundamental theorem of calculus
- The connection between the definite and indefinite integral
- Some standard integrals
Integration by substitution
Integration by parts
- Integration by parts
- One function is in the form xn and the other can be integrated at least n times
- One of the functions is sin(bx) or cos(bx) or a linear combination of them, the other is an exponential function
- We have only one function, but one we can differentiate, e.g. arcsine,
- One is a logarithm

Some various integrals
- The integral of sin(x)cos(x) dx,
- The integral of 1/(x^2-1),
- The integral of 1/( x^2+1),
- The integral of 1/sqrt(1-x^2) ,
- The integral of 1/sqrt(x^2-1) ,
- The integral of one over sqrt(x^2+1) ,
- The integral of sqrt(1-x^2) ,
- The integral of sqrt(x^2-1) ,
- The integral of sqrt(x^2+1) ,
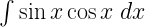


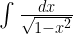


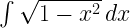

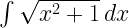
A rather peculiar rule
Some special integrals
- The integral
- The integral
- The integral
- The integral
- The integral
, a second way.



Previous page : The hyperbolic functions
Next page : Differential Equations